Awswrangler Read Csv
Awswrangler Read Csv - Web reading in chunks of 100 lines. Append (default) only adds new files without any. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],.
Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. Web reading in chunks of 100 lines. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Append (default) only adds new files without any.
>>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. Web reading in chunks of 100 lines. Append (default) only adds new files without any.

7ReadingCSVFilePart1 YouTube
Web reading in chunks of 100 lines. Append (default) only adds new files without any. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,.
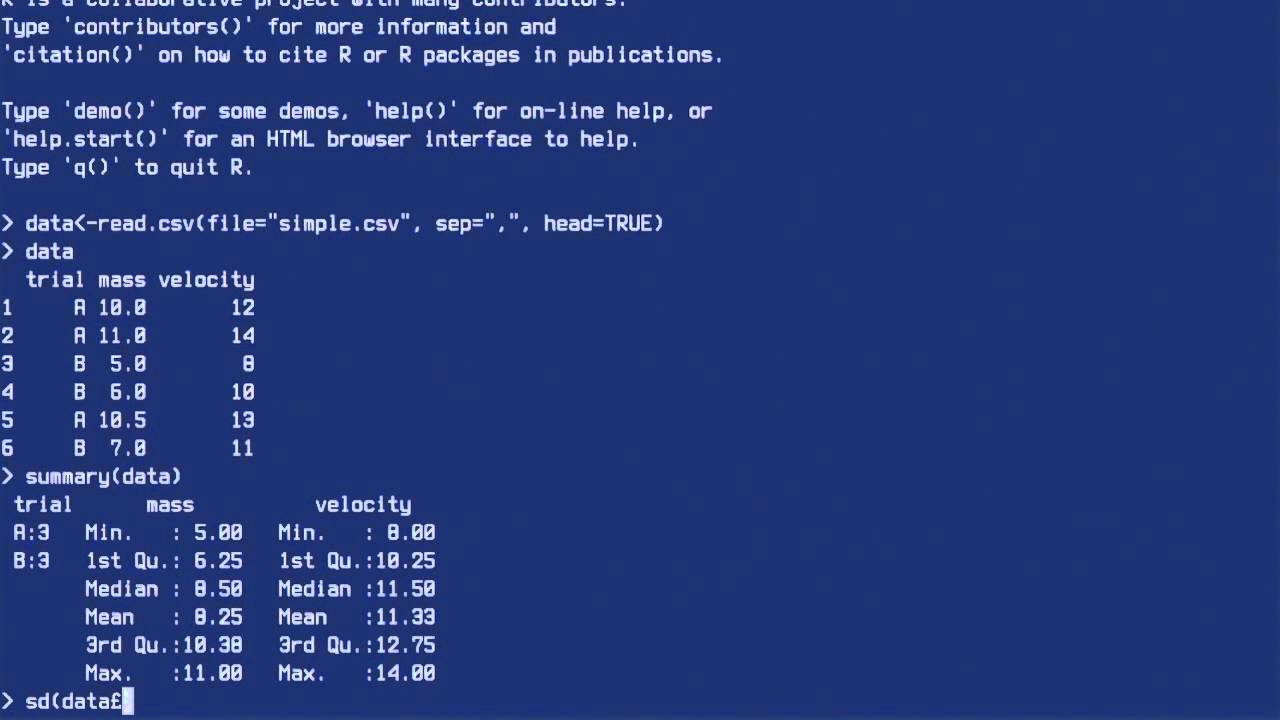
Using R to read a CSV file YouTube
Web reading in chunks of 100 lines. Append (default) only adds new files without any. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,.
How To Read ‘CSV’ File In Python Python Central
Append (default) only adds new files without any. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. Web reading in chunks of 100 lines. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],.

Pandas read_csv complete guide Machine Learning HD
Web reading in chunks of 100 lines. Append (default) only adds new files without any. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],.

How to Read CSV file in Java TechVidvan
Web reading in chunks of 100 lines. Append (default) only adds new files without any. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,.
How to Read csv Data Into R YouTube
Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. Web reading in chunks of 100 lines. Append (default) only adds new files without any. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],.

How to read a csv file in R Blog R
Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. Web reading in chunks of 100 lines. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Append (default) only adds new files without any.
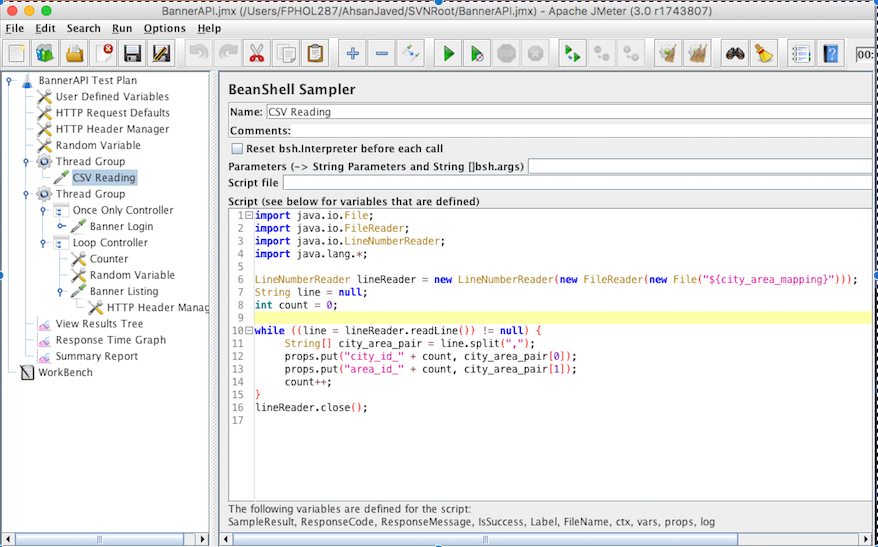
Reading CSV file only once in JMeter for all threads by Ahsan Javed
>>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Append (default) only adds new files without any. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. Web reading in chunks of 100 lines.

Write / Read CSV file YouTube
Web reading in chunks of 100 lines. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. Append (default) only adds new files without any.
![READ CSV in R 📁 (IMPORT CSV FILES in R) [with several EXAMPLES]](https://r-coder.com/wp-content/uploads/2020/05/read-csv-r.png)
READ CSV in R 📁 (IMPORT CSV FILES in R) [with several EXAMPLES]
Web reading in chunks of 100 lines. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],. Append (default) only adds new files without any. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,.
Web Reading In Chunks Of 100 Lines.
Append (default) only adds new files without any. Web easy integration with athena, glue, redshift, timestream, opensearch, neptune, quicksight, chime, cloudwatchlogs, dynamodb, emr,. >>> import awswrangler as wr >>> dfs = wr.s3.read_csv(path=['s3://bucket/filename0.csv', 's3://bucket/filename1.csv'],.