Spark Read From S3
Spark Read From S3 - Web reading files from s3 using pyspark is a common task for data scientists working with big data. Web 2 answers sorted by: Web 2 answers sorted by: Web the following example illustrates how to read a text file from amazon s3 into an rdd, convert the rdd to a dataframe, and then use the data source api to write the dataframe into a parquet file on amazon s3: Web reading files from s3 with spark locally. Web amazon emr offers features to help optimize performance when using spark to query, read and write data saved in amazon s3. Web june 14, 2023 this article explains how to connect to aws s3 from databricks. Web what chapter of the manga is season 3. For more information, see data storage considerations. I want to read all parquet files from an s3 bucket, including all those in the subdirectories (these are actually prefixes).
Web 2 answers sorted by: If you're talking about those 2 episodes that netflix thinks is s3… Specifying credentials to access s3 from spark Web the following example illustrates how to read a text file from amazon s3 into an rdd, convert the rdd to a dataframe, and then use the data source api to write the dataframe into a parquet file on amazon s3: For more information, see data storage considerations. Web reading data from s3 subdirectories in pyspark. Web with amazon emr release 5.17.0 and later, you can use s3 select with spark on amazon emr. Read a text file in amazon s3… To be more specific, perform read and write operations on aws s3 using apache spark. You are writing a spark job to process large amount of data on s3 with emr, but you might want to first understand the data better or test your spark job.
With these steps, you should be able to read any file from s3. Web you can read and write spark sql dataframes using the data source api. Web when spark is running in a cloud infrastructure, the credentials are usually automatically set up. Web spark sql provides spark.read.csv(path) to read a csv file from amazon s3, local file system, hdfs, and many other data sources into spark dataframe and. Web june 14, 2023 this article explains how to connect to aws s3 from databricks. To be more specific, perform read and write operations on aws s3 using apache spark. It will download all hadoop missing packages that will allow you to execute spark jobs with s3… For more information, see data storage considerations. Web the objective of this article is to build an understanding of basic read and write operations on amazon web storage service s3. Web reading files from s3 with spark locally.

Read and write data in S3 with Spark Gigahex Open Source Data
Web 2 answers sorted by: Databricks recommends using unity catalog external locations to connect to s3. Web reading files from s3 using pyspark is a common task for data scientists working with big data. For more information, see data storage considerations. To be more specific, perform read and write operations on aws s3 using apache spark.

Spark SQL Architecture Sql, Spark, Apache spark
Web with amazon emr release 5.17.0 and later, you can use s3 select with spark on amazon emr. Databricks recommends using unity catalog external locations to connect to s3. To be more specific, perform read and write operations on aws s3 using apache spark. Web reading files from s3 using pyspark is a common task for data scientists working with.

One Stop for all Spark Examples — Write & Read CSV file from S3 into
Web spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it’s advantages and how to read the parquet file from amazon s3 bucket into dataframe and write dataframe in parquet file to amazon s3. S3 select allows applications to retrieve only a subset of data from.

Spark Read and Write Apache Parquet Spark By {Examples}
S3 select allows applications to retrieve only a subset of data from an object. With these steps, you should be able to read any file from s3. Web reading files from s3 using pyspark is a common task for data scientists working with big data. Web the following example illustrates how to read a text file from amazon s3 into.

Spark에서 S3 데이터 읽어오기 내가 다시 보려고 만든 블로그
S3 select allows applications to retrieve only a subset of data from an object. Web reading files from s3 with spark locally. I have wanted to switch from watching the anime to reading the manga and i would like to know what chapter season 3 starts in the manga. Web spark sql provides spark.read.csv(path) to read a csv file from.

Tecno Spark 3 Pro Review Raising the bar for Affordable midrange
Web 2 answers sorted by: Web spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it’s advantages and how to read the parquet file from amazon s3 bucket into dataframe and write dataframe in parquet file to amazon s3. Web the objective of this article is.

Spark Read Json From Amazon S3 Spark By {Examples}
Web when spark is running in a cloud infrastructure, the credentials are usually automatically set up. With these steps, you should be able to read any file from s3. Web 2 answers sorted by: For more information, see data storage considerations. Web the following example illustrates how to read a text file from amazon s3 into an rdd, convert the.
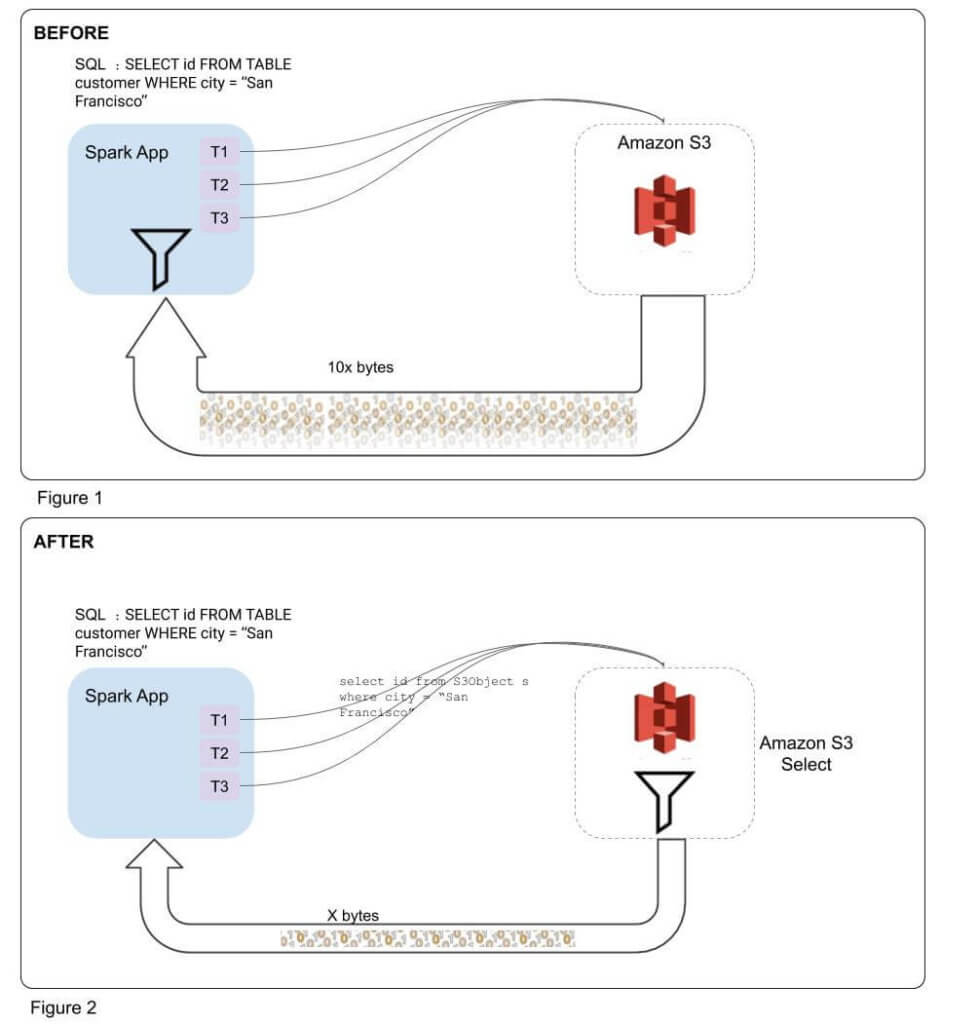
Improving Apache Spark Performance with S3 Select Integration Qubole
Specifying credentials to access s3 from spark I want to read all parquet files from an s3 bucket, including all those in the subdirectories (these are actually prefixes). Web reading files from s3 with spark locally. To be more specific, perform read and write operations on aws s3 using apache spark. Web spark sql provides spark.read.csv(path) to read a csv.

PySpark Tutorial24 How Spark read and writes the data on AWS S3
Web 2 answers sorted by: Read a text file in amazon s3… Web reading data from s3 subdirectories in pyspark. Web you can read and write spark sql dataframes using the data source api. Web the following example illustrates how to read a text file from amazon s3 into an rdd, convert the rdd to a dataframe, and then use.

Spark Architecture Apache Spark Tutorial LearntoSpark
Web the following example illustrates how to read a text file from amazon s3 into an rdd, convert the rdd to a dataframe, and then use the data source api to write the dataframe into a parquet file on amazon s3: Specifying credentials to access s3 from spark With these steps, you should be able to read any file from.
This Guide Has Shown You How To Set Up Your Aws Credentials, Initialize Pyspark, Read A File From S3, And Work With The Data.
Web 2 answers sorted by: To be more specific, perform read and write operations on aws s3 using apache spark. With these steps, you should be able to read any file from s3. Web what chapter of the manga is season 3.
Web Reading Data From S3 Subdirectories In Pyspark.
For more information, see data storage considerations. I have wanted to switch from watching the anime to reading the manga and i would like to know what chapter season 3 starts in the manga. Web spark read from & write to parquet file | amazon s3 bucket in this spark tutorial, you will learn what is apache parquet, it’s advantages and how to read the parquet file from amazon s3 bucket into dataframe and write dataframe in parquet file to amazon s3. Connect to s3 with unity catalog access s3 buckets using instance profiles access s3 buckets with uris and aws keys access s3.
Web The Following Example Illustrates How To Read A Text File From Amazon S3 Into An Rdd, Convert The Rdd To A Dataframe, And Then Use The Data Source Api To Write The Dataframe Into A Parquet File On Amazon S3:
Web reading files from s3 with spark locally. Web you can read and write spark sql dataframes using the data source api. Web june 14, 2023 this article explains how to connect to aws s3 from databricks. S3 select allows applications to retrieve only a subset of data from an object.
Web With Amazon Emr Release 5.17.0 And Later, You Can Use S3 Select With Spark On Amazon Emr.
Web amazon emr offers features to help optimize performance when using spark to query, read and write data saved in amazon s3. Databricks recommends using unity catalog external locations to connect to s3. S3 select can improve query performance for csv and json files in some applications by pushing down processing to amazon s3. Cloudera components writing data to s3 are constrained by the inherent limitation of amazon s3 known as eventual consistency.